Overview: ChIMES Active Learning Driver
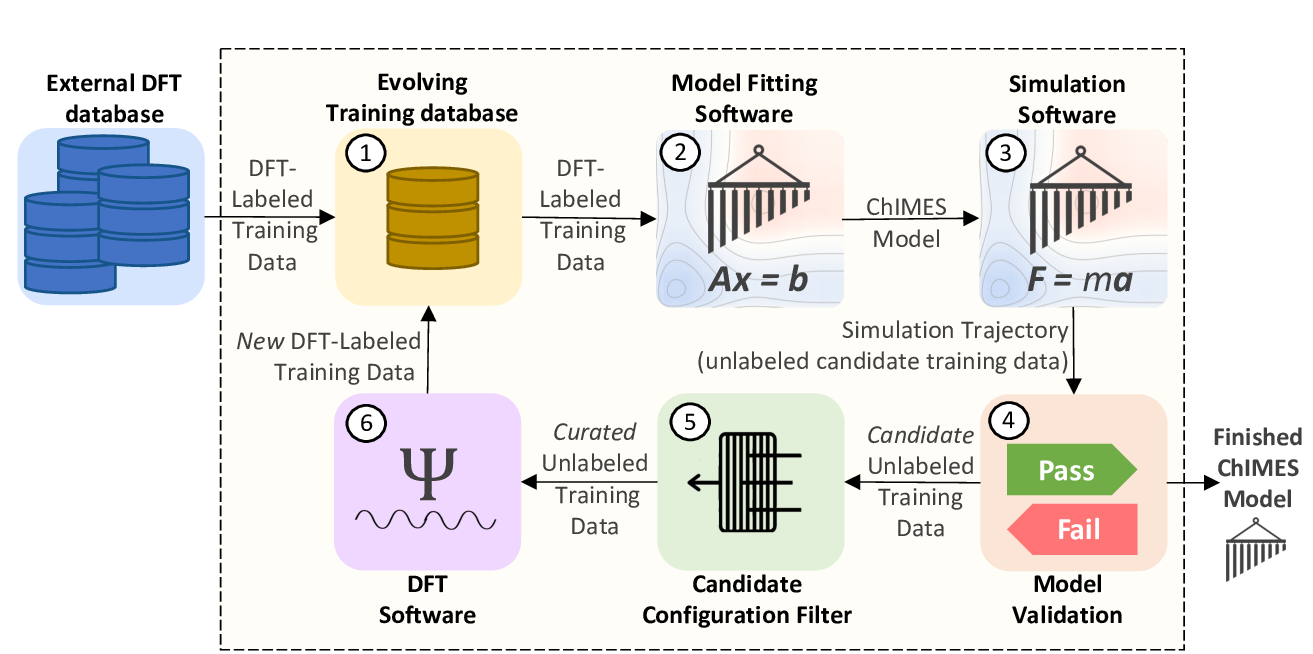
Fig. 1: The ChIMES Active Learning Driver Workflow.
In most cases, generating robust and accurate ChIMES models necesitates an interative fitting strategy. As shown in Fig. 1, this strategy begins with selecting a number of seed configurations from a larger quantum-based data set (e.g., DFT, which will be used henceforth), which are added to an evolving training database (i.e., Fig. 1 step 1). In Fig. 1 step 2, a ChIMES model of user-specified hyperparamters generated based on the training database constructured in step 1. Generated parameters are then used to launch one or more ChIMES simulations of user-specified nature (step 3).
Fig. 1 step 4 comprises user inspection for model validation. This could entail inspecting the root-mean-squared-error in the fit from step 2, the conserved quantity from simulations in step 3, or comparing physical properties predicted via the simulations in step 3 (e.g., radial pair distribution function) to those predicted by DFT. If the user is satisfied with model performance at this step, they can terminate the ALD and proceed to production simulations with their model; otherwise, the ALD proceeds to step 5.
The 5th step, i.e. “candiate configuration filter” comprises selection of candidate unlabeled training data for assignment of DFT forces, energies, and or stresses (step 6) and subsequent addition to the evolving training database (step 1). This iterative fitting process continues until either the user-specified number of cycles is complete, or until user-terminated.
Additional information on different execution modes as well as example scripts can be found below: